Accéder au contenu principal
Rechercher
Rechercher dans ce blog
David Romero Trejo
Sécurité des informations | Réseau
Articles
Affichage des articles du février, 2014
Tout afficher
février 24, 2014
RPO y RTO
février 17, 2014
Ciclo de vida de implantación de productos
février 10, 2014
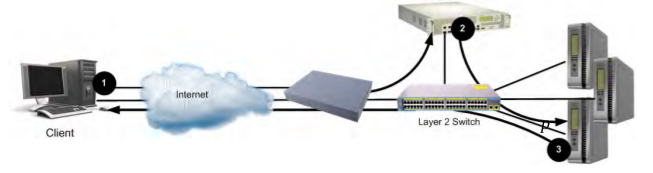
Global Server Load Balancing
février 03, 2014
Balanceadores de Carga
Articles plus récents
Articles plus anciens
Accueil