Accéder au contenu principal
Rechercher
Rechercher dans ce blog
David Romero Trejo
Sécurité des informations | Réseau
Articles
Affichage des articles du octobre, 2014
Tout afficher
octobre 27, 2014
¿Un DDoS legal?
octobre 20, 2014
Vulnerabilidad POODLE SSLv3
octobre 13, 2014
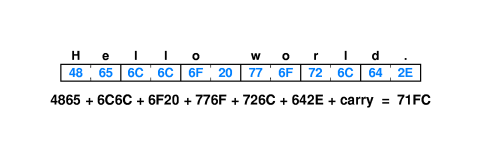
Checksum
octobre 06, 2014
DNS Load Balancing
Articles plus récents
Articles plus anciens
Accueil