Accéder au contenu principal
Rechercher
Rechercher dans ce blog
David Romero Trejo
Sécurité des informations | Réseau
Articles
Affichage des articles du mars, 2015
Tout afficher
mars 30, 2015
Enrutamiento Multicast
mars 23, 2015
Multi-Chassis Link Aggregation
mars 16, 2015
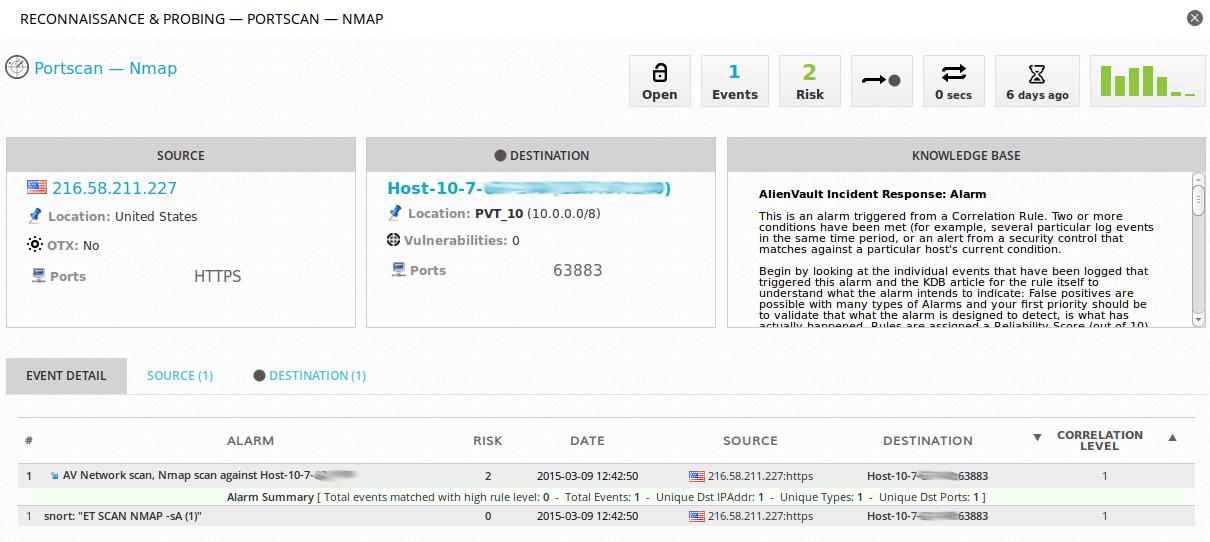
¿Google nos escanea?
mars 09, 2015
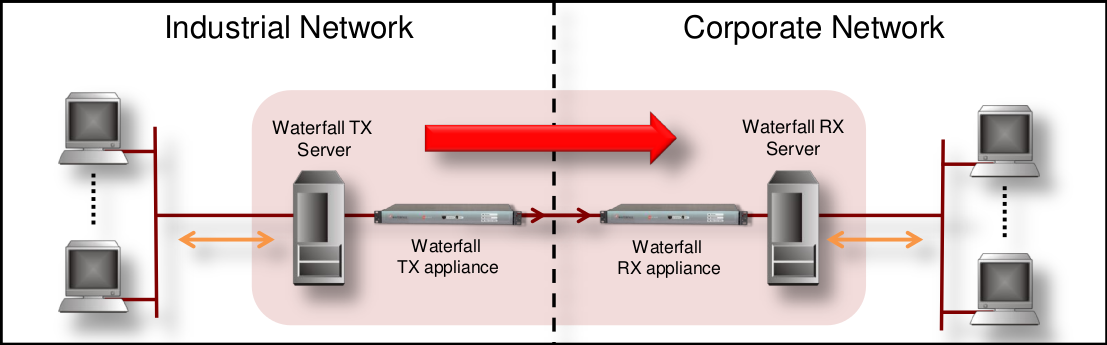
Unidirectional Security Gateways
mars 02, 2015
Algoritmo de Generación de Dominios
Articles plus récents
Articles plus anciens
Accueil